
Types of NoSQL databases
A NoSQL database provides a mechanism for storage and retrieval of data that is modeled in means other than the tabular relations used in relational databases. NoSQL is often interpreted as Not-only-SQL to emphasize that they may also support SQL-like query languages. Most NoSQL databases are designed to store large quantities of data in a fault-tolerant way.
NoSQL is simply the term that is used to describe a family of databases that are all non-relational. While the technologies, data types, and use cases vary wildly amount them, it is generally agreed that there are four types of NoSQL databases:
- Key-value stores – These databases pair keys to values. An analogy is a files system where the path acts as the key and the contents act as the file. There are usually no fields to update, instead, the entire value other than the key must be updated if changes are to be made. The simplicity of this scales well but it can limit the complexity of the queries and other advanced features. Examples are: Dynamo, MemcacheDB, Redis, Riak, FairCom c-treeACE, Aerospike, OrientDB, MUMPS, HyperDex, Azure Table Storage (see Redis vs Azure)
- Graph stores – These excel at dealing with interconnected data. Graph databases consist of connections, or edges, between nodes. Both nodes and their edges can store additional properties such as key-value pairs. The strength of a graph database is in traversing the connections between the nodes. But they generally require all data to fit on one machine, limiting their scalability. Examples include: Allegro, Neo4J, InfiniteGraph, OrientDB, Virtuoso, Stardog, Sesame
- Column stores – Relational databases store all the data in a particular table’s rows together on-disk, making retrieval of a particular row fast. Column-family databases generally serialize all the values of a particular column together on-disk, which makes retrieval of a large amount of a specific attribute fast. This approach lends itself well to aggregate queries and analytics scenarios where you might run range queries over a specific field. Examples include: Accumulo, Cassandra, Druid, HBase, Vertica
- Document stores – These databases store records as “documents” where a document can generally be thought of as a grouping of key-value pairs (it has nothing to do with storing actual documents such as a Word document). Keys are always strings, and values can be stored as strings, numeric, Booleans, arrays, and other nested key-value pairs. Values can be nested to arbitrary depths. In a document database, each document carries its own schema — unlike an RDBMS, in which every row in a given table must have the same columns. Examples include: Lotus Notes, Clusterpoint, Apache CouchDB, Couchbase, MarkLogic, MongoDB, OrientDB, Qizx, Cloudant, Azure DocumentDB (see MongoDB vs. Azure DocumentDB and An Overview of Microsoft Azure DocumentDB)




The CAP Theorem states that it is impossible for a distributed computer system to simultaneously provide all three of the following guarantees:
- Consistency (all nodes see the same data at the same time)
- Availability (a guarantee that every request receives a response about whether it succeeded or failed)
- Partition tolerance (the system continues to operate despite arbitrary message loss or failure of part of the system)

Since you can only pick two guarantees, here is a list of NoSQL system broken out by the two that they support:

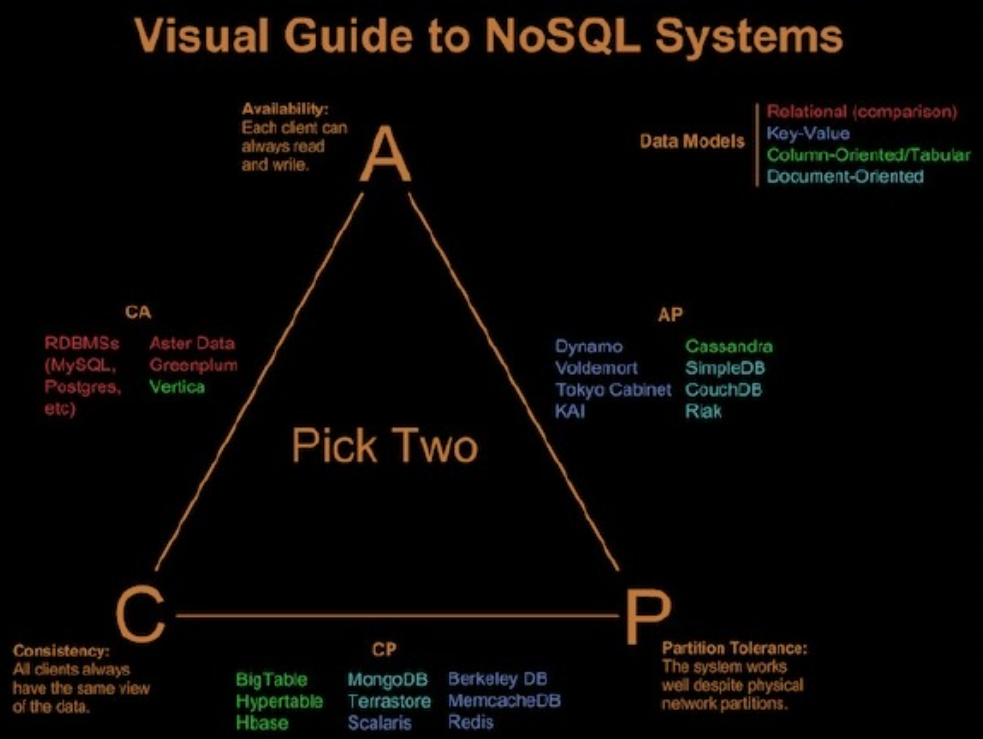{kind=link}
Here is a quick summary of the most popular NoSQL products by group:
- Key-value stores
- Riak – Offers high availability, fault tolerance, operational simplicity, and scalability. Riak is one of the more sophisticated data stores. It offers most of the features found in others, then adds more control over duplication. Although the basic structure stores pairs of keys and values, the options for retrieving them and guaranteeing their consistency are quite rich.
- Redis – Like CouchDB and MongoDB, Redis stores documents or rows made up of key-value pairs. Unlike the rest of the NoSQL world, it stores more than just strings or numbers in the value. It will also include sorted and unsorted sets of strings as a value linked to a key, a feature that lets it offer some sophisticated set operations to the user. There’s no need for the client to download data to compute the intersection when Redis can do it at the server. Redis is also known for keeping the data in memory and only writing out the list of changes every once and a bit. Some don’t even call it a database, preferring instead to focus on the positive by labeling it a powerful in-memory cache that also writes to disk. Traditional databases are slower because they wait until the disk gets the information before signaling that everything is OK. Redis waits only until the data is in memory, something that’s obviously faster but potentially dangerous if the power fades at the wrong moment.
- Document stores
- MongoDB – Is designed for scale, flexible data aggregation and to store files of any size. It has rich querying, high availability and full indexing support and is fast being adopted by many businesses. Uses GridFS instead of HDFS. MongoDB is designed for OLTP workloads. It can do complex queries, but it’s not necessarily the best fit for reporting-style workloads. Or if you need complex transactions, it’s not going to be a good choice. However, MongoDB’s simplicity makes it a great place to start. MongoDB eschews the traditional table-based relational database structure in favor of JSON-like documents with dynamic schemas (MongoDB calls the format BSON), making the integration of data in certain types of applications easier and faster. MongoDB is built to store data as an object in a dynamic schema, instead of a tabular database like SQL.
- Coachbase – Can be used both as a document database that stores JSON documents or a pure key-value database. Click here for how it compares to MongoDB. CouchDB stores documents, each of which is made up of a set of pairs that link key with a value. The most radical change is in the query. Instead of some basic query structure that’s pretty similar to SQL, CouchDB searches for documents with two functions to map and reduce the data. One formats the document, and the other makes a decision about what to include.
- Column stores
- Cassandra – Born at Facebook and built on Amazon’s Dynamo and Google’s BigTable, it is a distributed storage system for managing very large amounts of structured data spread out across many commodity servers, while providing highly available service with no single point of failure. It is essentially a hybrid between a key-value and a column-oriented (or tabular) database. Most agree it is better than Hbase and MongoDB. It can be used for both OLTP and data warehousing. It replaces HDFS with the Cassandra File System (CFS). Cassandra does not support joins or subqueries and emphasizes denormalization.
- HBase – Patterned after Google BigTable, HBase is designed to provide fast, tabular access to the high-scale data stored on HDFS. It is well suited for sparse data sets, which are common in many big data use cases. HBase offers two broad use cases. First, it gives developers database-style access to Hadoop-scale storage, which means they can quickly read from or write to specific subsets of data without having to wade through the entire data store. Most users and data-driven applications are used to working with the tables, columns, and rows of a database, and that’s what HBase provides. Second, HBase provides a transactional platform for running high-scale, real-time applications. In this role, HBase is an ACID-compliant database that can run transactional applications. That’s what conventional relational databases like Microsoft SQL Server are mostly used for, but HBase can handle the incredible volume, variety, and complexity of data encountered on the Hadoop platform. Like other NoSQL databases, it doesn’t require a fixed schema, so you can quickly add new data even if it doesn’t conform to a predefined model. It can be used for lightweight OLTP. Tables are de-normalized for speed (so no joins), but updates can be slow. HBase does not use Hadoop’s MapReduce capabilities directly, though HBase can integrate with Hadoop to serve as a source or destination of MapReduce jobs
- Graph
- Neo4j – Neo4J lets you fill up the data store with nodes and then add links between the nodes that mean things. Social networking applications are its strength. The code base comes with a number of common graph algorithms already implemented. If you want to find the shortest path between two people — which you might for a site like LinkedIn — then the algorithms are waiting for you.
- OrientDB – It is a document-based database, but the relationships are managed as in graph databases with direct connections between records. It supports schema-less, schema-full and schema-mixed modes. It has a strong security profiling system based on users and roles and supports SQL as a query language. OrientDB uses a new indexing algorithm called MVRB-Tree, derived from the red–black tree and from the B+ tree; this reportedly has benefits of having both fast insertions and fast lookups.

But I’ll leave you with this note: Although NoSQL databases are becoming more popular, according to DB-Engines Ranking they only make up about 12% of the total database market when you include relational databases!
More info:
Thumbtack: NoSQL Database Comparison by Ben Engber
MongoDB, Cassandra, and HBase — the three NoSQL databases to watch
DB-Engines database popularity ranking
NoSQL showdown: MongoDB vs. Couchbase
NoSQL standouts: New databases for new applications
The Rise and Fall of the NoSQL Empire (2007–2013)
What’s better for your big data application, SQL or NoSQL?
Considerations for using NoSQL technology on your next IT project
Difference between SQL and NoSQL : Comparision
SQL vs NoSQL Database Differences Explained with few Example DB
Getting Acquainted with NoSQL on Windows Azure
Data Store Map (full PDF map) – 451 Research
Which NoSQL Solution is Right For You?
Four and a Half Types of NoSQL Databases, and When to Use Them
Understanding NoSQL on Microsoft Azure
I have been tracking NoSQL database systems for several years. There are also other issues, such as skills, that are important to consider. Some discussion: Considerations for using NoSQL technology on your next IT project.
A good example of a NoSQL database is CryptonorDB (cloud – mobile database). It delivers high availability, fault tolerant database service accessible via a RESTful HTTP/JSON API and it is built with security in mind.
Pingback:What is Polyglot Persistence? - SQL Server - SQL Server - Toad World
Pingback:What is Polyglot Persistence? | James Serra's Blog
Pingback:Hadoop and Microsoft | James Serra's Blog
Pingback:Relational databases vs Non-relational databases | James Serra's Blog
Pingback:DB Weekly No.55 | ENUE
Pingback:Why use a data lake? | James Serra's Blog